- Load Balancers
- MPLS
- Service-discovery
- Replication
- Data Store Replication
- Quick Response / Low latency
- Scalability
- Multiple PoPs (point of presence)
- Minimal Latency and lowest amount of tarffic via public internet
- High availiability (HA)
- 5 9’s in aggregate failures
- HA for Load balancer (LB)
- HA for Call Control app server
- Media Server HA
- Security against malicious attacks
- MITM
- DDOS
- Identifying outages , logs and pcap analysis + alerting
- Bottlenecks
- Performance testing
- Distributed Data Store
- Distributed-event-management-and-event-driven-architecture-using-streams
- Distributed cache for call control Servers
- Circuits – fail fast , wait for circuit to recover before calling again
Load Balancers
Load Balancer(LB) is the initial point of interaction between the client application and the core system. It is pivotal in the distribution of the load across multiple servers and ensuring the client is connected to the nearest VoIP/SIP application server to minimize latency. However, the load balancers are also susceptible to security breaches and DOS attacks as they have a public-facing interface. This section lists the protocols, types and algorithms used popularly in Load balancers of VoIP systems.
| software LB | Layer 4 / hardware LB |
| Nginx Amazon ELB ( eleastic load balanecr) | F5 BIG-IP load balancer CISCO system catalyst Barracuda load balancer NetScaler |
| used by applications in cloud ADN (Application delivery network) | used by network address translators (NATs) DNS load balancing |
Load Balancers(LB) ping each server for health status and greylists servers that are unhealthy( respond late) as they may be overloaded or experiencing congestion. The LB monitors it rechecks after a while and if a server is healthy ( ie if a server responds with responds with status update) it can resume sending traffic to it. LB should also be distributed to different data centres in primary-secondary setup for HA.
Networking protocol
| TCP Loadbalancer | HTTP load balancers | SIP based LB as Kamailio/ Opensips |
| can forwrad the packet without inspecting the content of the packet. | terminate the connection and look inside the request to make a load balcing decsiion for exmaple by using a cookie or a header. | domain specific to VoIP |
| (+) fast, can handle million of req per second | (+) handle SIP routing based on SIP headers and prevent flooding atacks and other malicious malformed packets from reaching application server |
Load balancing algorithms
- Weighted Scheduling Algorithm
- Round Robin Algorithm
- Least Connection First Scheduling
- Lest response time algorithms
- Hash based algorithm ( send req based on hashed value such as suing IP address of request URL)
| Loadbalancer | Reverse Proxy |
| forward proxy server allows multiple clients to route traffic to an external server | accepts clients requestd for server and also returns the server’s response to the client ie routes traffic on behalf of multiple servers. |
| Balances load and incoming traffic endpoint | public facing endpoint for outgoing traffic additional level of abstraction and security, compression |
| used in SBC (session border controllers) and gateways |
Service Discovery
Client-side or even backend service discovery uses a broadcasting or heartbeat mechanism to keep track of active servers and deactivates unresponsive or failed servers. This process of maintaining active servers helps in faster connection time. Some approaches to Service Discovery
- Mesh
- (-) exponentially incresing network traffic
- Gossip
- Distributed cache
- Coordination service with Service
- (-) requesres coordination service for leader selection
- (-) needs consensus
- (-) RAFT and pbFT for mnaging failures
- Random leader selection
- (+) quicker
- (-) may not gurantee one leader
- (-)split brain problem
Keepalive, unregistering unhealthy nodes
Systems such as Consul, Etcd, and Zookeeper can help services find each other by keeping track of registered names, addresses, and ports. Health checks help verify service integrity and are often done using an HTTP endpoint.
Replication
Usuallay there is a tradeoff between liveness and safety.
- Single leader replication
- (-) vulnerable to loss of data is leader goes down before replication completes
- used to in sql
- multileader replication and
- leaderless replication
- (-) increases latencies
- (-) quorem based on majority , cannot function is majority node are not down
- used in cassandra
Data Store Replication
For Relatonal Dataabase

For NoSQL databse replication and HA

Quick Response / Low latency
Message format
| Textual Message format | Binary Message Format |
| human readbale like json xml | diff to comprehend , need shared schema between sender and receiver to serilaize and deserialze , |
| names for every field adds to size | no field name or only tags , reduces message size |
Gateways for faster routing and caching to services
gateways are single entry point to route user requests to backend services .
Separate hot storage from cold storage
hot storage is frquently accessed data which must be near to server
cold storage is less frequently accessed data such as archives
- object storage
- slow access
Scalability
To make a system :-
- scalable : use partitioing
- reliable : use replication and checkpointing to not loose data in failures
- fast : use in -memory usage
According to CAP theorem Consistency and Availiability are difficult to achieve together and there has to be a tradeof acc to requirnments.
Partitioining
Partition strategy can be based on various ways such as :-
- Name based partition
- geographic partition
- names’ hashed value based on identifier
- (-) can lead to hot partitions ( high density in areas of freq accessible identioers )
- (-) high density spots for example all messages with a null key to go to the same partition
- (-) doesnt scale
- event time based hash
- (+) data is spread evenly over time
To create a well distributed partition we could spread hot partition into 2 partitions or dedicate partitions for freq accessible items. An effective partitioning keys uses
- Cardinality : total num of unique keys for a usecase. High cardinality leads to better distribution.
- high cardinatility keys : names , email address , url since they have high variatioln
- low cardinatlity keys : boolean flags such as gender M/F
- Selectivity : number of message with each key. High selectivity leads to hotspots and hence low selectivity is better for even distribution.

Autoscalling
Scale Out not Up !
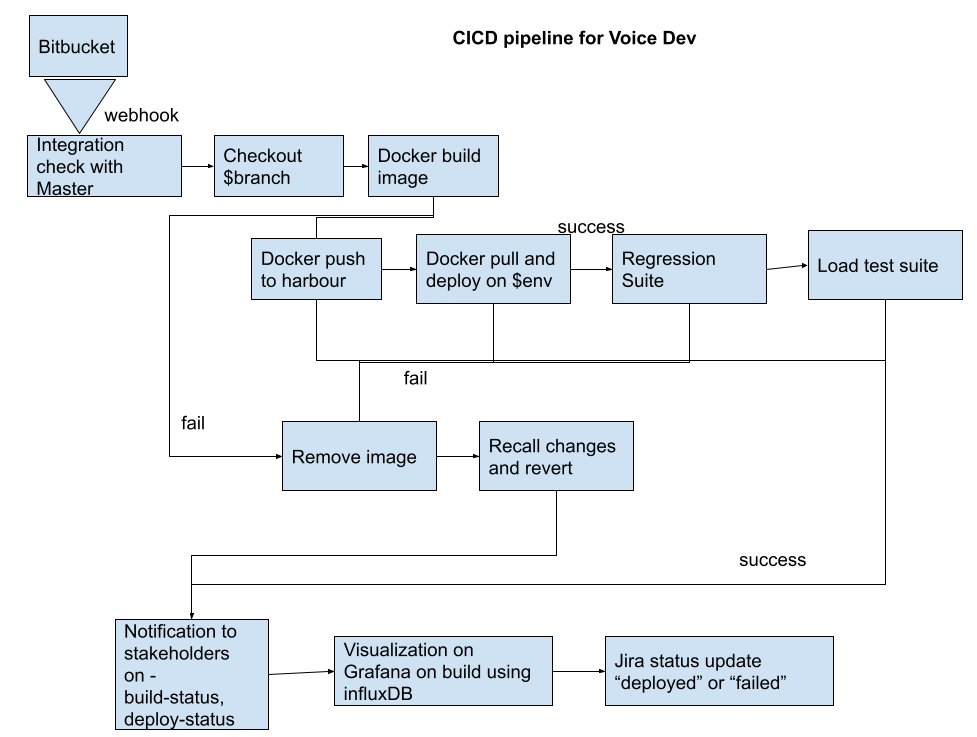
Kubernetes is an open-source container-orchestration system for automating computer application deployment, scaling, and management used in DevOps. I have mentioned this in detail on the article on VoIP and DevOps below.
Multiple PoPs (point of presence)
for a VOIP system catering to many clients accross the globe or accessing multiple carriers meant for different counteries based on Prefix matching , there should be alocal PoP in most used regions . typically these regions include – US east – west coasts, UK – germany of London , Asia Pacific – Mumbai ,Hong Kong and Australia.

Minimal Latency and lowest amount of tarffic via public internet
Creating multiple POPs and enabling private traffic via VPN in between them ensures that we use the backbone of our cloud provider such as AWS or datacentre instead of traversing via public internet which is slower and more insecure. Hopping on a private interface between the cloud server and maintaining a private connection and keepalive between them helps optimize the traffic flow while keeping the RTT and latency low.

HA ( High-availability )
Some factors affecting Dependability are
- Eventual Consistency
- MultiRegion failover
- Disaster Recovery
A high-availability (HA) architecture implies Dependability.Usually via existence of redundant applications servers for backups: a primary and a standby. These applications are configured so that if primary fails, the other can take over its operations without significant loss of data or impact to business operations.
Downtime / SLA of 5 9’s in aggregate failures
4 9’s of availiability on each service components gives a downtime of 53 mins per service each year. However in aggregate failure this could amlount to (99.99)10 = 99.9 downtime which is 8-10 hours each year.

Thus, aggregate failure should be taken into consideration while designing reliable systems.
HA for Proxy / Load balancer (LB)
A LB is the first point of contact for outbound calls and usually does not save the dialogue information into memory or database but still contain the transaction information in memory. In case the LB crashes and has to restart, it should
- have a quick uptime
- be able to handle in dialogue requests
- handle new incoming dialogue requests in a stateless manner
- verify auth/authorization details from requests even after restart
HA for Call Control app server
App server is where all the business logic for call flow management resides and it maintains the dialog information in memory.
Issues with in-memory call states : If the VM or server hosting the call control app server is down or disconnected, then live calls are affected, this, in turn, causes revenue loss. Primarily since the state variable holding the call duration would be able to pass onto the CDR/ billing service upon the termination of the call. For long-distance, multi telco endpoint calls running hours this could be a significant loss.
- Standby app server configuration and shared memory : If the primary app server crashes the standby app server should be ready to take its place and reads the dialog states from the shared memory.
- Live load balanced secondary app server + external cache for state varaibles : External cache for state variables: a cluster of master-slave caches like Redis is a good way of maintaining the dialogue state and reading from it once the app server recovers from a failed state or when a secondary server figures it has a missing variable in local memory.
Media Server HA
Assuming the kamailio-RTPengine duo as App server and Media Server. These components can reside in same or different VMs. Incase of media server crash, during the process of restoring restarted RTpengine or assigning a secondary backup RTpengine , it should load the state of all live calls without dropping any and causing loss of revenue . This is achived by
- external cache such as Redis ,
- quick switchover from primary to secondary/fallback media server and
- floating IPs for media servers that ensures call continuity inspite of failure on active media server.
Architecturally it looks the same as fig above on HA for the SIP app server.
Security against malicious attacks
Attacks and security compromisation pose a very signficant threat to a VoIP platform.
MITM attacks
Man in midddle attacks can be counetred by
- End to end encryption of media using SRTP and signals using TLS
- Strong SIP auth mechanism using challenges and creds where password is composed of mixed alphanumeric charecters and atleast 12 digits long
- Authorization / whitelisting based on IP which adheres to CIDR notation
DDOS attacks
DDOS renders a particular network element unavailable, usually by directing an excessive amount of network traffic at its interfaces.
dDOS – multiple network hosts to flood a target host with a large amount of network traffic. Can be created by sending falsified sip requests to other parties such that numerous transactions originating in the backwards direction comes to the target server created congestion.
Can be counetred by
- detect flooding and q in traffic and use Fail2ban to block
- challenge questionable requests with only a single 401 (Unauthorized) or 407 (Proxy Authentication Required)
Read about SIP security practices in deatils https://telecom.altanai.com/2020/04/12/sip-security/
Other important factors leading to security
- Keystores and certificate expiry tracker
- priveligges and roles
- Test cases and code coverage
- Reviewers approval before code merge
- Window for QA setup and testing , to give go ahead before deployment
Identifying outages and Alerting
Raise Event notification alerts to designated developers for any anolous behavior. It could be call based or SMS basef alert based on the sevirity of the situtaion .

Sources for alert manager
- Build failed ( code crashes, Jenkins error)
- Deployment failed ( from Kubernetes , codechef, docker ..)
- configuration errors ( setting VPN etc )
- Server logs
- Server health
- homer alerts ( SIP calls responses 4xx,5xx,6xx)
- PCAP alerts ( Malformed SIP SDP ..)
- Internal Smoke test ( auto testing procedure done routinely to check live systems )
- Support tickets from customer complaints ( treat these as high priority since they are directly impacting customers)
Bottlenecks
The test bed and QA framework play a very crticial role in final product’s credibility and quality.
Performance Testing
- Stress Testing : take to breaking
- Load Testing : 2x to 3x testing
- Soak Testing : typical network load to long time ( identify leaks )
Robust QA framework( stress and monkey testing) to identify potential bottlenecks before going live
A QA framework basically validates the services and callflows on staging envrionment before pushing changes to production. Any architectural changes should especially be validated throughly on staginng QA framework befire making the cut. The qualities of an efficient QA platform are :
Genric nature – QA framework should be adatable to different envrionments such as dev , staging , prod
Containerized – it should be easy to spn the QA env to do large scale or small scale testing and hence it should be dockerized
CICD Integration and Automation – integrate the testcases tightly with gt post push and pull request creation . Minimal Latency and lowest amount of tarffic via public internet
Keep as less external dependecies as possible for exmaple a telecom carrier can be simulated by using an PBX like freeswitch or asterix
Asynchronous Run – Test cases should be able to run asynchronously. Such as seprate sipp xml script for reach usecase
Sample Testcases for VoIP
- Authentication before establish a session
- Balance and account check before establishing a session like whitelisting , blacklisting , restricted permission in a particular geography
- Transport security and adaptibility checks , TLS , UDP , TCP
- codec support validation
- DTMF and detection
- Cross checking CDR values with actual call initiator and terminator party
- cross checking call uuid and stats
- Validating for media and related timeouts
QA frameworks tools – Robot framework
traffic monitor – VOIP monitor
customer simulator – sipP scripts
network traffic analyser – wireshark
pcap collevcter – tcpdump , sngrep
Distributed Data Store
A Distributed Database Design could have many components. It could work on static datastore like
- SQL DB where schema is important
- MySQL
- postgress
- Spanner – Globally-distributed database from Google
- NoSQL DB for to store records in json
- Cassandra – Distributed column-oriented database
- Cache for low latency retrivals
- Memcached – Distributed memory caching system
- Redis – Distributed memory caching system with persistence and value types
- Data lakes for heavy sized data
- AWS s3 object storage
- blob storage
- File System
- Google File System (GFS) – Distributed file system
- Hadoop File System (HDFS) – Open source Distributed file system
or work on realtime data streams
- Batch processing ( Hadoop Mapreduce)
- Stream processing ( Kafka + spark)
- Kafka – Pub/sub message queue
- Cloud native stream processing ( kinesis)
Each component has its own pros and cons. The choice depends on requirnments and scope for system behaviour like
- users/customer usuage and expectation ,
- Scale ( read and write )
- Performnace
- Cost
| Users/customers | Scale ( read / write) | Performance | Cost |
| Who uses the system ? How the system will be used? | Read / writes per second ? Size of data per request ? cps ( calls or click per second) ? | write to read delay ? p99 latency for read querries ? | should design minimize the cost of development ? should design mikn ize the cost of mantainance ? |
| spikes in traffic | eventual consistency ( prefer quick stale data ) as compared to no data at all | ||
| redundancy for failure management |
Some fundamental constrains while design distributed data structure :-
p99 latency : 99% of the requests should be faster than given latency. In other words only 1% of the requests are allowed to be slower.
Request latency:
min: 0.1
max: 7.2
median: 0.2
p95: 0.5
p99: 1.3
Inidiviual Events vs Aggregate Data
| Inidividual Events ( like every click or every call metric) | Aggregate Data ( clicks per minute, outgoing calls per minute) |
| (+) fast write (+) can customize/ recalculate data from raw | (+) faster reads (+) data is fready for decision making / statistics |
| (-) slow reads (-) costlier for large scale implementations ( many events ) | (-) can only query in the data as was aggregates ( no raw ) (-) requires data aggregation pipeline (-) hard to fix errors |
| suitable for realtime / data on fly low expected data delay ( minutes ) | suitable for batch processing in background where delay is acceptable from mintes to hours |
Push vs Pull Architecture
Push : A processing server manages state of varaible in memory and pushes them to data store.
- (-) crashed processingserver means all data is lost
Pull : A temporary data strcyture such as a queue manages the stream of data and processing service pull from it to process before pusging to data stoore.
- (+) a crashed server has to effect on temporarily queue held data and new server can simply take on where previous processing server left.
- (+) can use checkpointing
Popular DB storage technologies
| SQL | NoSQL |
| Structured and Strict schema Relational data with joins | Semi-structured data Dynamic or flexible schema |
| (+) faster lookup by index | (-) data intensive workload (+) high throughput for IOPS (Input/output operations per second ) |
| used for Account information transactions | best suitable for Rapid ingest of clickstream and log data Leaderboard or scoring data Metadata/lookup tables |
| DynamoDB – Document-oriented database from Amazon MongoDB – Document-oriented database |
A NoSQL databse can be of type
- Quorem
- Document
- Key value
- Graph
Cassandra is wide column supports asyn master less replication
Hinge base also a quorem based db also has master based preplication
MongoDB documente orientd DB used leacder based replication
SQL scaling patterns include:
- Federation/ federated database system : transparently maps multiple autonomous database systems into a single virtual/federated database.
- (-) slow since it access multiple data storages to get the value
- Sharding / horizontal partition
- Denormalization : Even though normalization is more memory efficient denormalization can enhance read performance by additing redundant pre computed data in db or grouping related data.
- Normalizing data reduces data warehouse disk space by reducing data duplication and dimension cardinality. In its full definition, normalization is the process of discarding repeating groups, minimizing redundancy, eliminating composite keys for partial dependency and separating non-key attributes.
- SQL Tuning : “iterative process of improving SQL statement performance to meet specific, measurable, and achievable goals”
Influx DB : to store time series data
AWS Redshift
Apache Hadoop
Redis
Embeed Data : RocksDB
Message Queues(Buffering) vs Batch Processing
Distributed event management, monitoring and working on incoming realtime data instead of stored Database is the preferred way to churn realtime analysis and updates. The multiple ways to handle incoming data are
- Batch processing – has lags to produce results, not time crtical
- Data stream – realtime response
- Message Queues – ensures timely sequence and order
| Buffering | Batching |
| Add events to buffer that can be read | Add events to batch and send when batch is full |
| (+) can handle each event | (+) cost effective (+) ensures throughput (-) if some events in batch fail should whole batch fail ? (-) not suited for real time processing |
| S3 like objects storage + Hadoop Mapreduce for processing |
Timeout
- Connection timeout : use latency percentiles to calculate this
- Request timeout
Retries
- exponential backoff : increase waiting time each try
- jitter : adds rabdomness to retry intervals to spread out the load.
Grouping events into object storage and Message Brokers

slower than stream processing but faster than batch processing.
Distributed Event management and Event Driven architecture using streams
In event driven archietcture a produce components performs and action which creates an event thata consumer/listener would subscribes to consume.
- (+) time sensitive
- (+)Asynch
- (+) Decoupled
- (+) Easy scaling and Elasticity
- (+) Heterogeneous
- (+) contginious

Expanding the stream pipeline

Event Streams decouple the source and sink applications. The event source and event sinks (such as webhooks) can asynchronously communicate with each other through events.
Options for stream processing architectures
- Apache Kafka
- Apache Spark
- Amazon kinesis
- Google Cloud Data Flow
- Spring Cloud Data Flow
Here is a post from earlier which discusses – Scalable and Flexible SIP platform building, Multi geography Scaled via Universal Router, Cluster SIP telephony Server for High Availability, Failure Recovery, Multi-tier cluster architecture, Role Abstraction / Micro-Service based architecture, Load Balancer / Message Dispatcher, Back end Dynamic Routing and REST API services, Containerization and Auto Deployment, Auto scaling Cloud Servers using containerized images.
Lambda Architecture
Stream processing on top of map reduce and stream processing engine. In lambda architecture we can send events to batch system and stream processing system in parallel. The results are stiched together at query time.

Apache Kafka is used as source which is a framework implementation of a software bus using stream-processing. “.. high-throughput, low-latency platform for handling real-time data feeds”.
Apache Spark : Data partitioning and in memory aggregation.
Distributed cache for call control Servers
| Dedicated Cache Cluster | Co located cache |
| Isolates cache fro service Cache and service do not share memory and CPU can scale independently can be used by many microservices flexibility in choosing hardware | doesnt require seprate hardware low operational and hardware cost scales together with the service |

Choosing cache host
- Mod function
- (-) behaves differently when a new client is added or one is removed , unsuitable for prod
- Consistent hashing ( chord)
- maps each value to a point on circle

Cache Replacement
Least Recently Used Cache Replacement

Consistency and High Availiability in Cache setup
ReadReplicas live in differenet data centre for disaster recovery.
Strong consistency using Master Slave

Circuits – fail fast, wait for circuit to recover before using again
Design patterns for a circuit base setup to gracefully handle exceptions using fallback.
Circuit breaker : stops client from repeatedly trying to exceute by calculate the error threshold.

Isolated thread pool in circuits and ensure full recovery before calling the service again.
(+) Circuit breaker event causes the entire circuit to repair itself before attempting operations.
References :
- [1] http://highscalability.com/blog/2013/4/15/scaling-pinterest-from-0-to-10s-of-billions-of-page-views-a.html
- [2] http://engineering.hackerearth.com/2013/10/07/scaling-database-with-django-and-haproxy/
- [3] Mastering Chaos – A Netflix Guide to Microservices , QCon London
- [4] https://dzone.com/refcardz/event-stream-processing-essentials
- [5] p99 latency https://stackoverflow.com/questions/12808934/what-is-p99-latency
- [6] Oracle site on partitioing- https://docs.oracle.com/en-us/iaas/Content/Streaming/Concepts/partitioningastream.htm
- [7] Mastering Chaos – A Netflix Guide to Microservices https://www.youtube.com/watch?v=CZ3wIuvmHeM&ab_channel=InfoQ
- [8] Netflix cloud architecture https://netflixtechblog.com/tagged/cloud-architecture
